2025莞纺大数据竞赛队
CentOS 7.9 大数据基础配置
Linux虚拟机IP分配
Hadoop+JDK配置
Zookeeper集群配置
Kafka配置
Hadoop搭建
数据可视化总结
数据分析总结
CentOS 7.9 基础指令大全
Flume安装配置
MySQL安装配置与运维
用户画像数据库表及数据.sql
本文档使用 OkDoc 发布
-
+
首页
数据可视化总结
## 数据可视化 什么是==数据可视化==? 数据可视化是为了使得数据更高效地反应数据情况,便于让读者更高效阅读,通过数据可视化突出数据背后的规律,以此突出数据中的重要因素 做这些之前必须不能忘记的就是导入模块和设置中文字体 ```python #导入模块 import matplotilb.pyplot as plt import pandas as pd #设置中文字体(常见可视化库中 默认字体通常不支持中文字体 所以要收到指定中文的字体) plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False ``` --- 做数据分析和数据可视化的时候一直都离不开的一个包: ### ==pandas== Pandas 的主要数据结构是 Series(一维数据)和 DataFrame(二维数据) 在比赛中用的最多pandas的就是读取数据和简单处理数据 ```python # 读取数据 df=pd.read_csv('xxx.csv') # 数据处理 df.groupby() # 数据分组 df['数据列'].value_counts() #数据统计 df['数据列'].mean() #平均 df.iloc[0] # 选择数据第一列 0,1,2,3以此类推 df.groupby('分组列名')['计算列名'].sum() #按什么分组计算总数量 #提取时间 #1.转换为datetime格式 df['时间列名']=pd.to_datetime(df['时间列名']) #2.提取时间特征 df['年']=df['时间列名'].dt.year #提取年份 df['月']=df['时间列名'].dt.month # 提取月份(1-12) df['日'] = df['时间列名'].dt.day # 提取日期(1-31) df['小时'] = df['时间列名'].dt.hour # 提取小时(0-23) df['分钟'] = df['时间列名'].dt.minute # 提取分钟(0-59) df['星期几'] = df['时间列名'].dt.dayofweek # 提取星期几(0=周一,6=周日) df['季度'] = df['时间列名'].dt.quarter # 提取季度(1-4) df[df['数据列']=='筛选内容'] #数据筛选 df[df['年份']==2022] #筛选出2022年的数据 ``` --- ### ==matplotilb== Matplotlib 是 Python 中最流行的数据可视化库之一,它提供了丰富的绘图功能,可以创建高质量的静态、动态和交互式图表。 >i **plt常用配置** > > **** Figure:对图的整体设置 Title:标题 Gird:网格 Xlabel/ylabel:设置x,y轴标题 Xticks/yticks:设置x,y轴刻度 Xlim/ylim:设置x,y轴的刻度范围 Legend:设置图例 --- #### 柱状图 ```python import pandas as ps import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('sale_car.csv') #设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False #使用柱状图展示2022每个月的汽车总销量,每个柱子代表一个月份,其高度代表该月的汽车总销量 # 1.筛选数据 df_2022=df[df[年份]==2022] #2.按月份分组计算总销量 mon=df_2022.groupby('月份')['销量'].sum().sort_index() #创建柱状图 plt.figure(figsize=(12,8)) plt.bar(mon.index,mon.values,color='skyblue') plt.title('2022年每月汽车总销量') plt.xlabel('月份') plt.ylabel('总销量') plt.xticks(range(1,13)) plt.tight_layout() plt.show() ``` 输出结果: 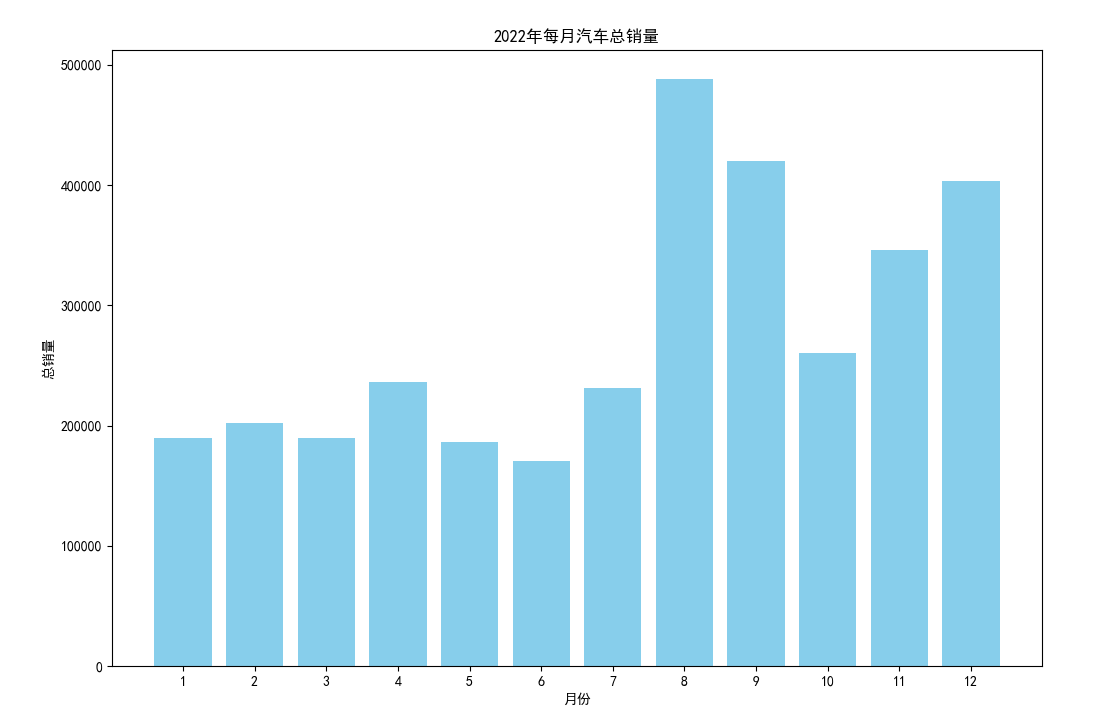 --- ```python import pandas as pd impory matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('restaurant.csv') # 设置中文字体 plt.rcParmas['font.sans-serif']=['SimHei'] plt.rcParmas['axes.unicode_minus']=False # 创建柱状图展示各地区餐厅数量 a=df['地区'].value_counts() plt.figure=(figsize=(12,8)) plt.bar(a.index,a.values,color='skyblue') plt.title('各地区餐厅数量柱状图') plt.xlabel('地区') plt.ylabel('餐厅数量') plt.tight_layouy() plt.show() ``` 输出结果: 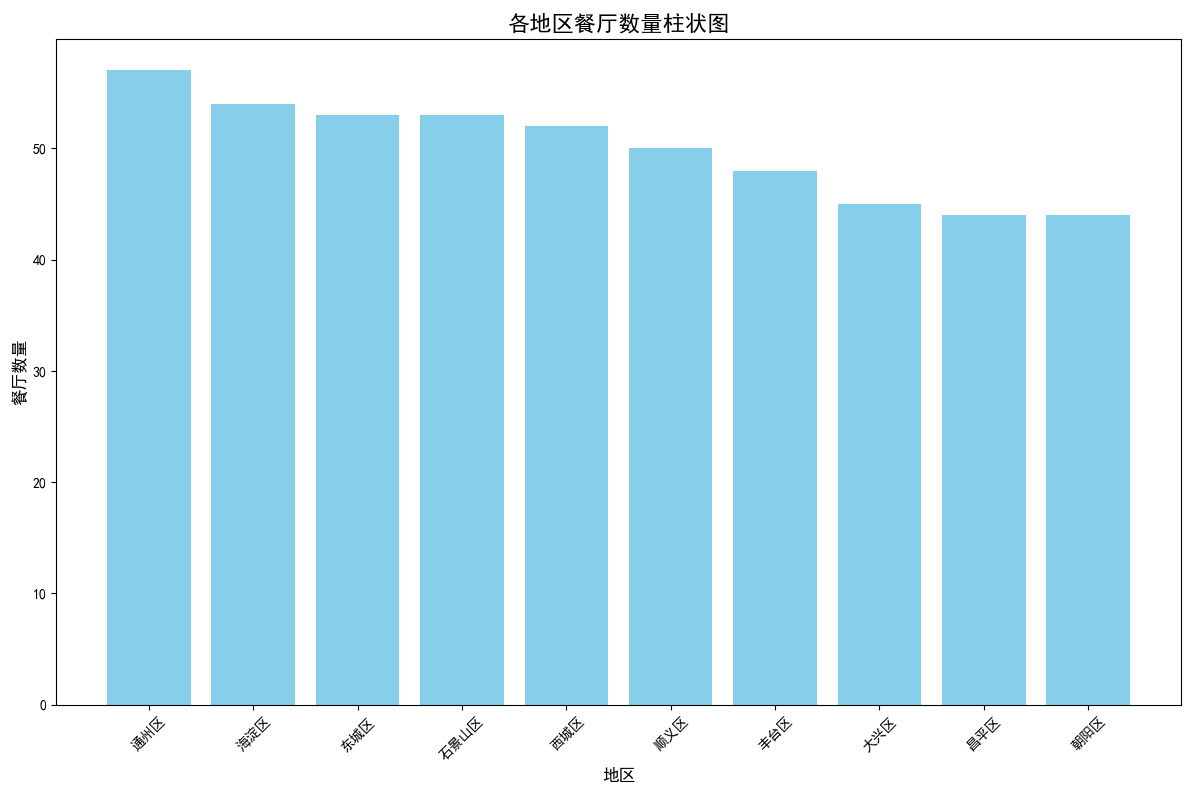 --- ```python import pandas as pd import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('house_sales.csv') #设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False #创建柱状图展示各市区的二手房销售数量,柱状图的每条柱子代表一个市区,高度代表该市区的房源销售数量 sq=df['市区'].value_counts() plt.figrue(figsize=(12,8)) plt.bar(sq.index,sq,values,color='skyblue') plt.title('各市区二手房销售数量') plt.xlabel('市区') plt.ylabel('销售数量') plt.tight_layout() plt.show() ``` 输出结果: 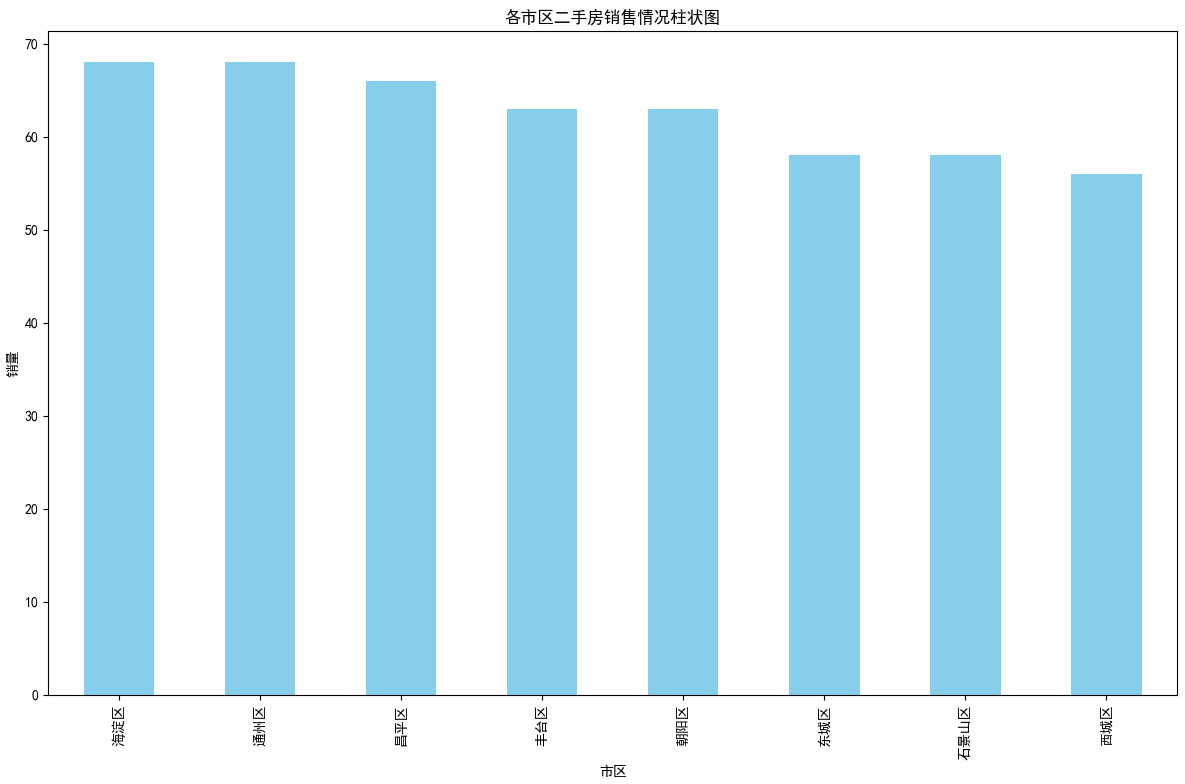 --- ```python import pandas as pd import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('hotel_csv') #设置中文字体 plt.rcParams['font-sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False # 使用柱状图展示各个地区的酒店数量,柱状图的每个柱子代表一个地区,高度代表该地区的酒店数量 jd=df['地区'].value_counts() plt.figure(figsize=(12,8)) plt.bar(jd.index,jd.values,color='skyblue') plt.xlabel('地区') plt.yalbel('酒店数量') plt.tight_layout() plt.show() ``` 输出结果: 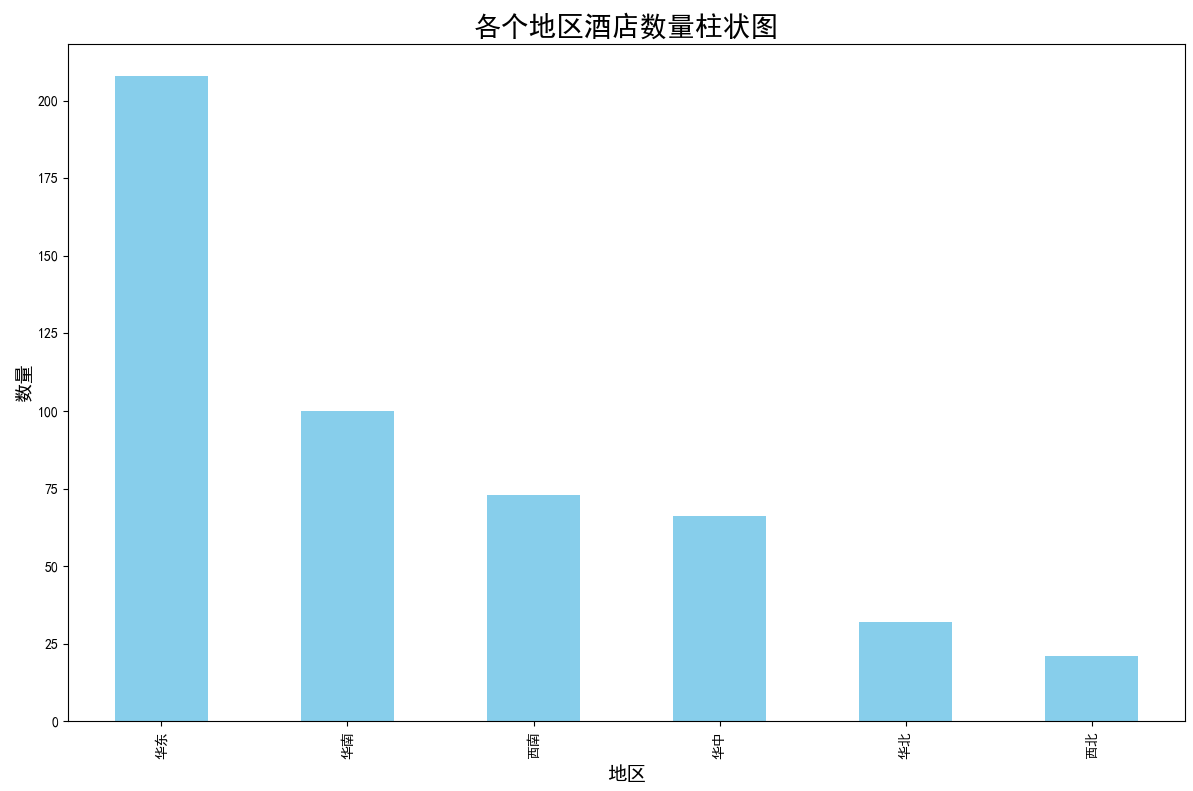 --- #### 条形图 ```python import pandas as pd import matplotlib.pyplot as plt #读取数据 df=pd.read_csv('sale_car.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False #创建条形图比较不同厂商的年度总销量,每个条形代表一个品牌,其长度表示该品牌的总销量 pp=df('厂商')['销量'].sum().sort_index() #创建条形图 plt.figrue(figsize=(12,8)) plt.barh(pp.index,pp.values,color='dkyblue') plt.title('不同厂商年度总销量') plt.xlabel('总销量') plt.ylabel('厂商') plt.tight_layout() plt.show() ``` 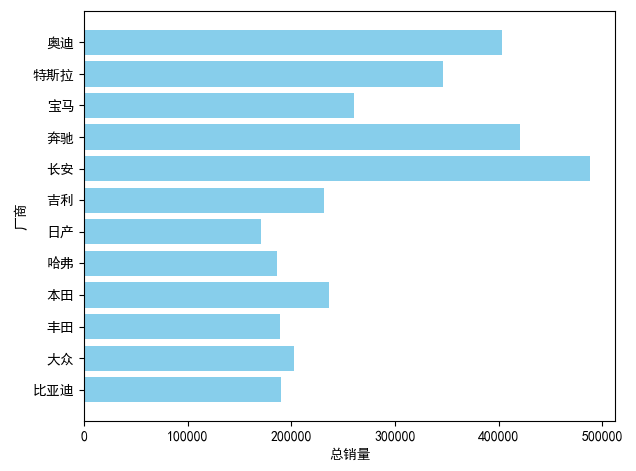 --- ```python import pandas as pd import matplotlib.pyplot as plt #读取数据 df=pd.read_csv('house_sales.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False #创建条形图比较不同户型的平均售价,条形图中横轴表示平均售价,纵轴表示户型 hux=df.groupby('户型')['价格(万元)'].mean() plt.figure(figsize=(12,8)) plt.barh(hux.index,hux.values,color='skyblue') plt.title('不同户型平均售价') plt.xlabel('平均售价') plt.ylabel('户型') plt.tight_layout() plt.show() ``` 输出结果: 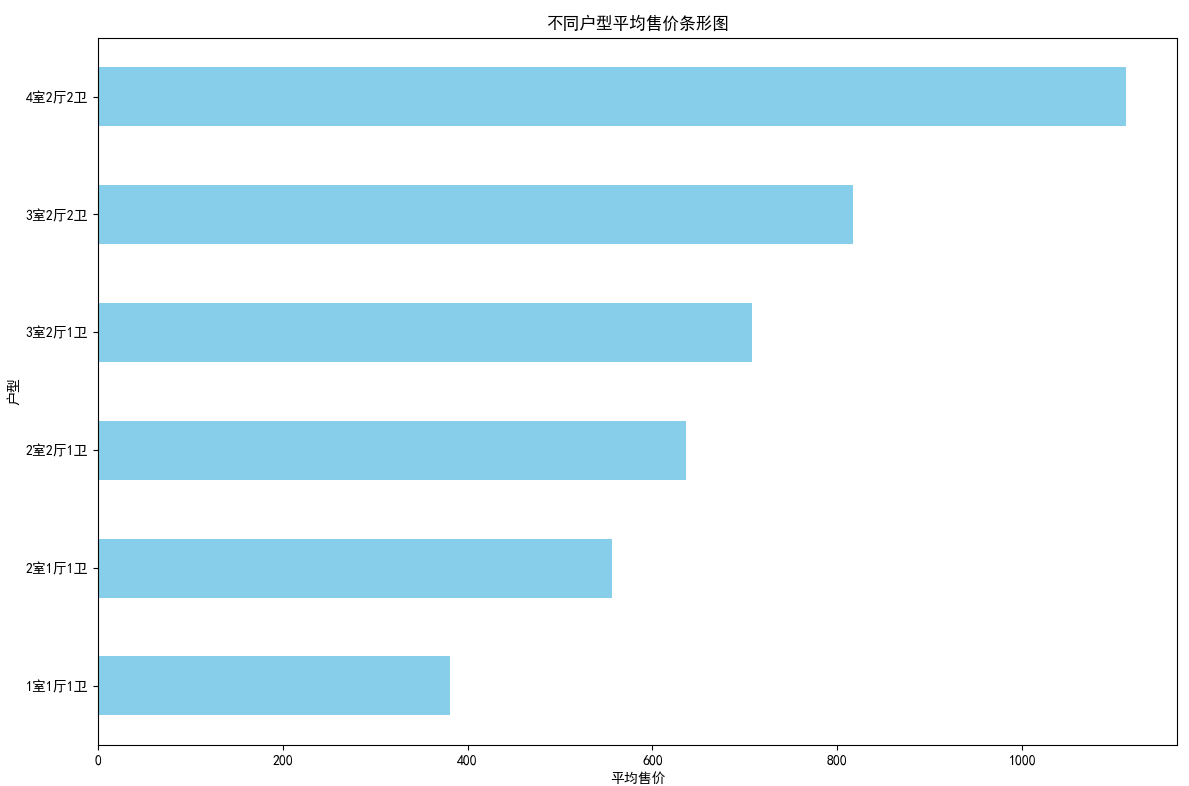 --- **==多行条形图==** ```python import pandas as pd import matplotlib.pyplot as plt #读取数据 df=pd.read_csv('hotel.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False #创建条形图比较不同地区的平均卫生评分和服务评分,条形图中横轴表示评分,纵轴表示地区,每个地区有个条形,分别表示卫生和服务评分 pf=df.groupby('地区')[['卫生评分','服务评分']].mean() pf.plot.barh(figsize=(12,8),color=[['skyblue','orange']) plt.title('不同地区的平均卫生评分和服务评分') plt.xlabel('平均评分') plt.yabel('地区') plt.tight_layout() plt.show() ``` 输出结果: 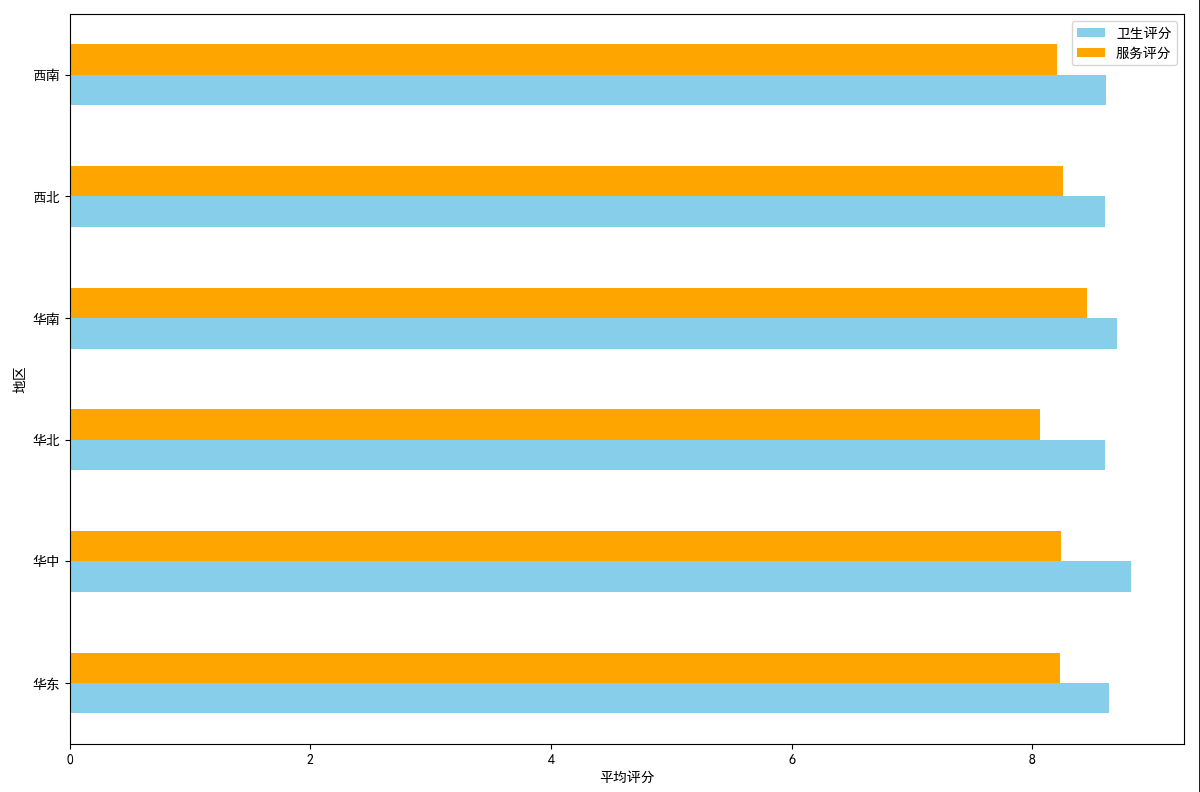 --- #### 散点图 ```python import pandas as pd import matplotlib.pyplot as plt #读取数据 df=pd.read_csv('restaurant.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False #使用散点图探索人均消费与评价数量之间的关系 plt.figure(figsize=(12,8)) plt.scatter(df['人均消费'],df['评价数'],alpha=0.6) plt.title('人均消费与评价数量之间的关系') plt.xlabel('人均消费') plt.ylabel('评价数量') plt.tight_layout() plt.show() ``` 输出结果: 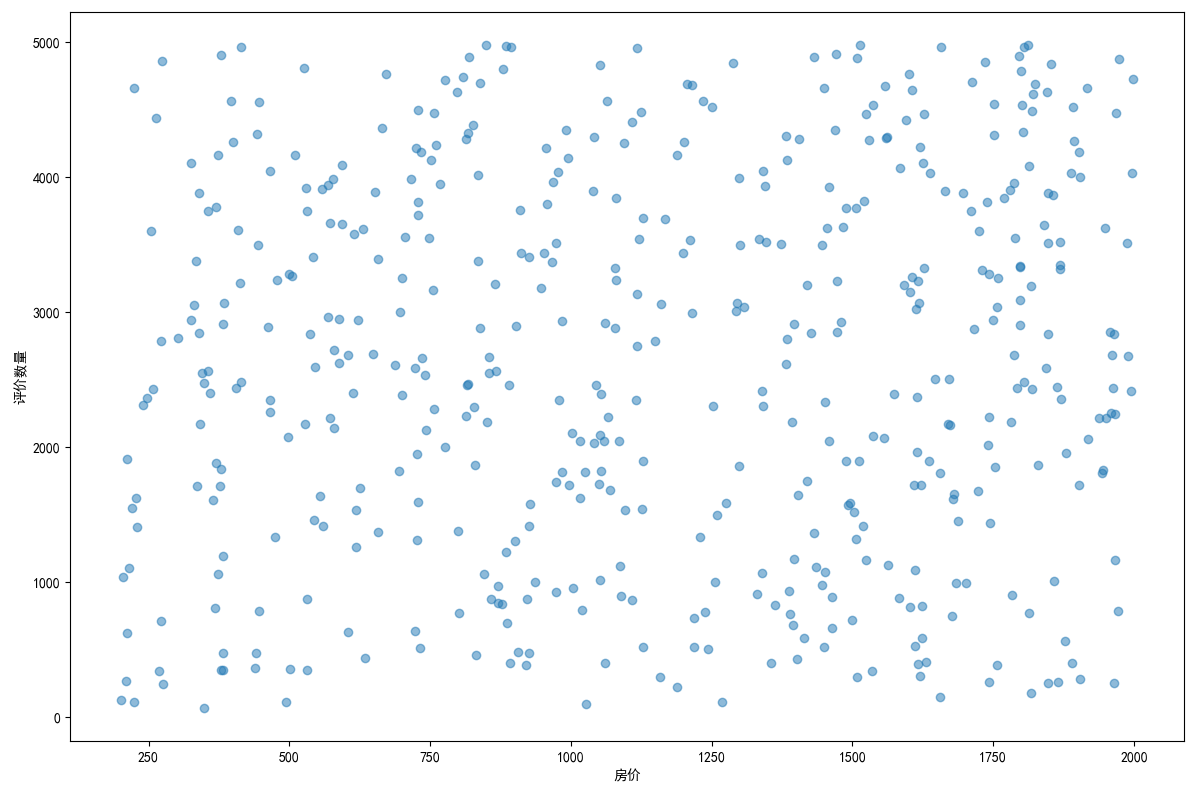 --- ```python import pandas as pd import matplotlib.pyplot as plt #读取数据 df=pd.read_csv('house_sales.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False #制作散点图探索售价与面积之间的关系,散点图中的横轴为售价,纵轴为面积,每个点代表一套房源 plt.figure(figsize=(12,8)) plt.scatter(df['价格(万元)'],df['面积(㎡)'],alpha=0.6) plt.title('售价与面积之间的关系') plt.xlabel('售价') plt,ylabel('面积') plt.tight_layout() plt.show() ``` 输出结果:  --- ```python import pandas as pd import matplotlib.pyplot as plt #读取数据 df=pd.read_csv('sale_car.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False #创建散点图探索车型售价(车型售价取平均值)与销量直接的关系,每个点代表一个车型,其位置根据该车型的售价和销量 sj=df.groupby('车型')['售价'].mean() xl=df.groupby('车型')['销量'].sum() plt.figure(figsize=(12,8)) plt.scatter(sj,xl,alpha=0.6) plt.title('车型平均售价与总销量关系') plt.xlabel('平均售价(万元)') plt.ylabel('总销量') plt.grid(True,alpha=0.3) plt.tight_layout() plt.show() ``` 输出结果: 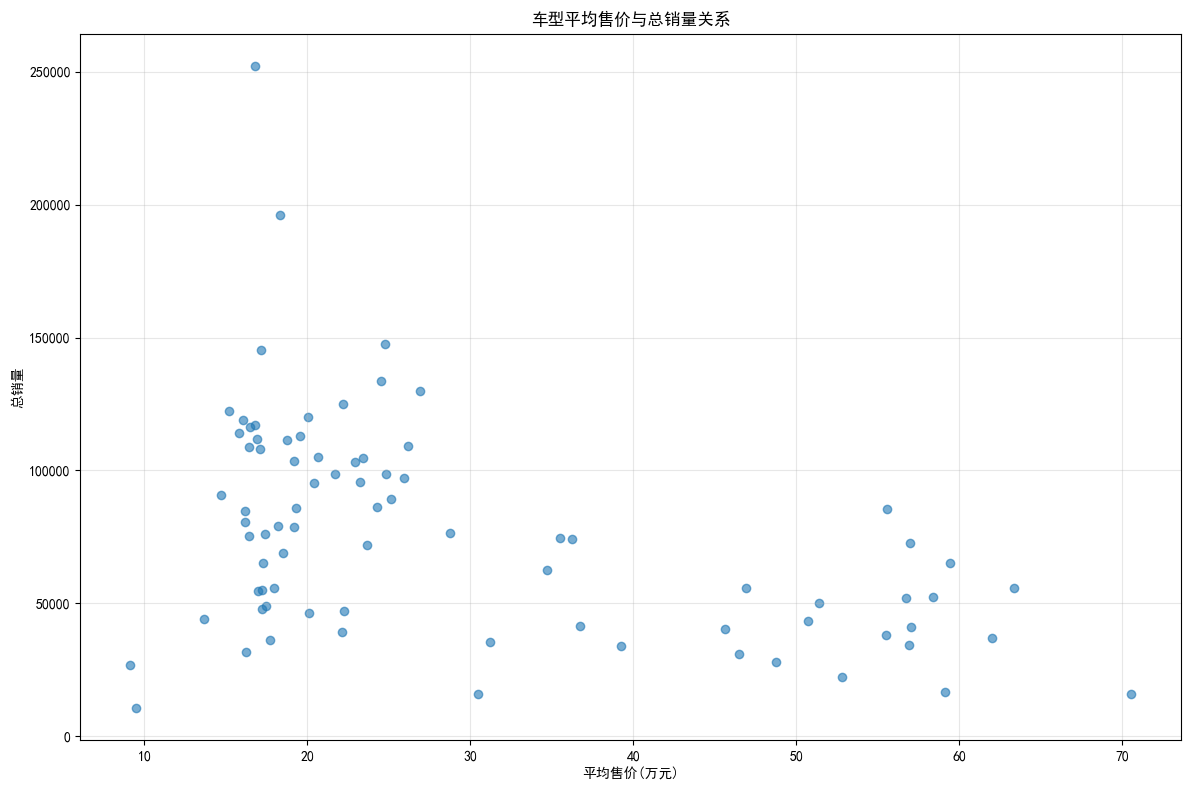 --- ```python import pandas as pd import matplotlib.pyplot as plt #读取数据 df=pd.read_csv('hotel.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False # 制作散点图探索房价和评价数量之间的关系,散点图中的横轴为房价,纵轴为评价数量,每个点代表每一家酒店 plt.figure(figsize=(12,8)) plt.scatter(df['房价 '],df['评价数'],alpha=0.6) plt.title('房价和评价数量之间的关系') plt.xlabel('房价') plt.ylabel('评价数量') plt.tight_layout() plt.show() ``` 输出结果: 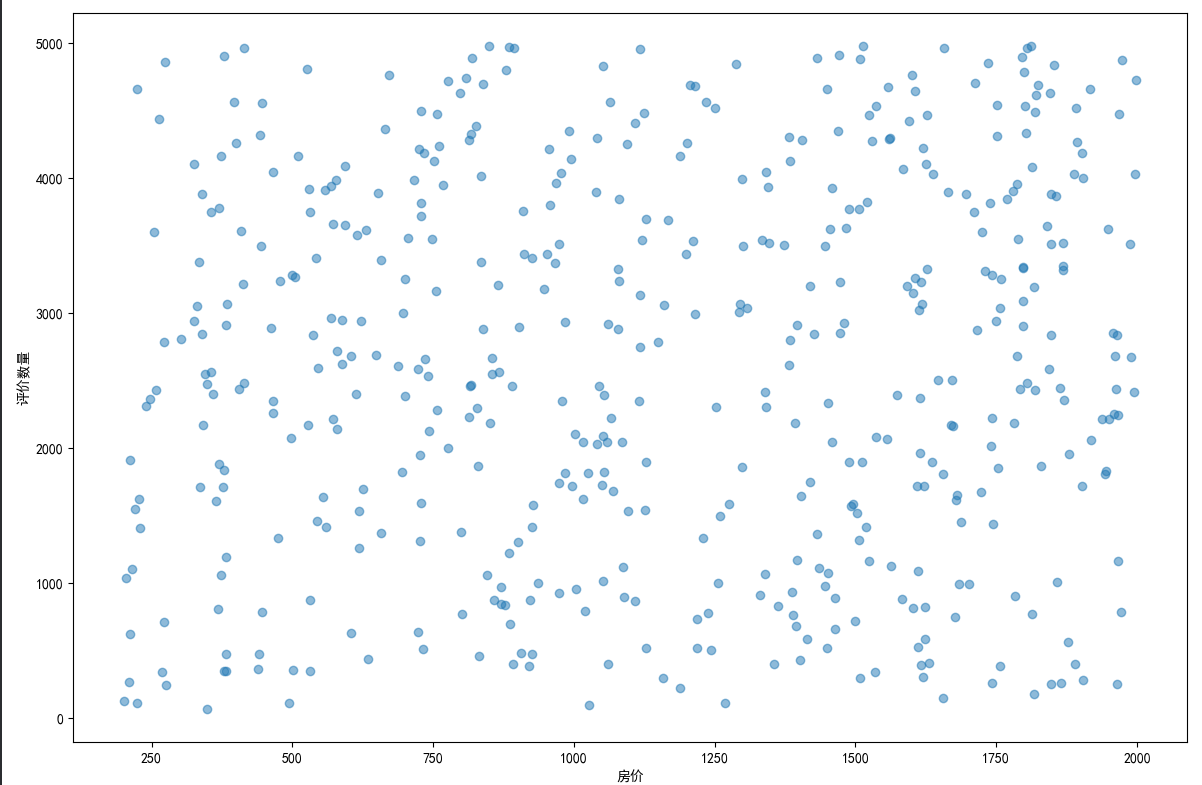 --- ```python import pandas as pd import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('bike_rides.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=Fales # 创建散点图分析气温与骑行量的关系,横轴为温度,纵轴为日骑行量,每个点的大小表示平均骑行时长,颜色表示天气状况 tq={'晴朗':0,'多云':1,'阴天':2,'小雨':3,'雾霾':4} x=df['天气状况'].map(tq) y=df['骑行时长(分钟)'].mean() plt.figure(figsize=(12,8)) plt.scatter(df['温度'],df['骑行时长'],s=y,c=x,alpha=0.6) plt.title('气温与骑行量的关系') plt.xlabel('温度') plt.ylabel('日骑行量') plt.tight_layount() plt.show() ``` 输出结果: 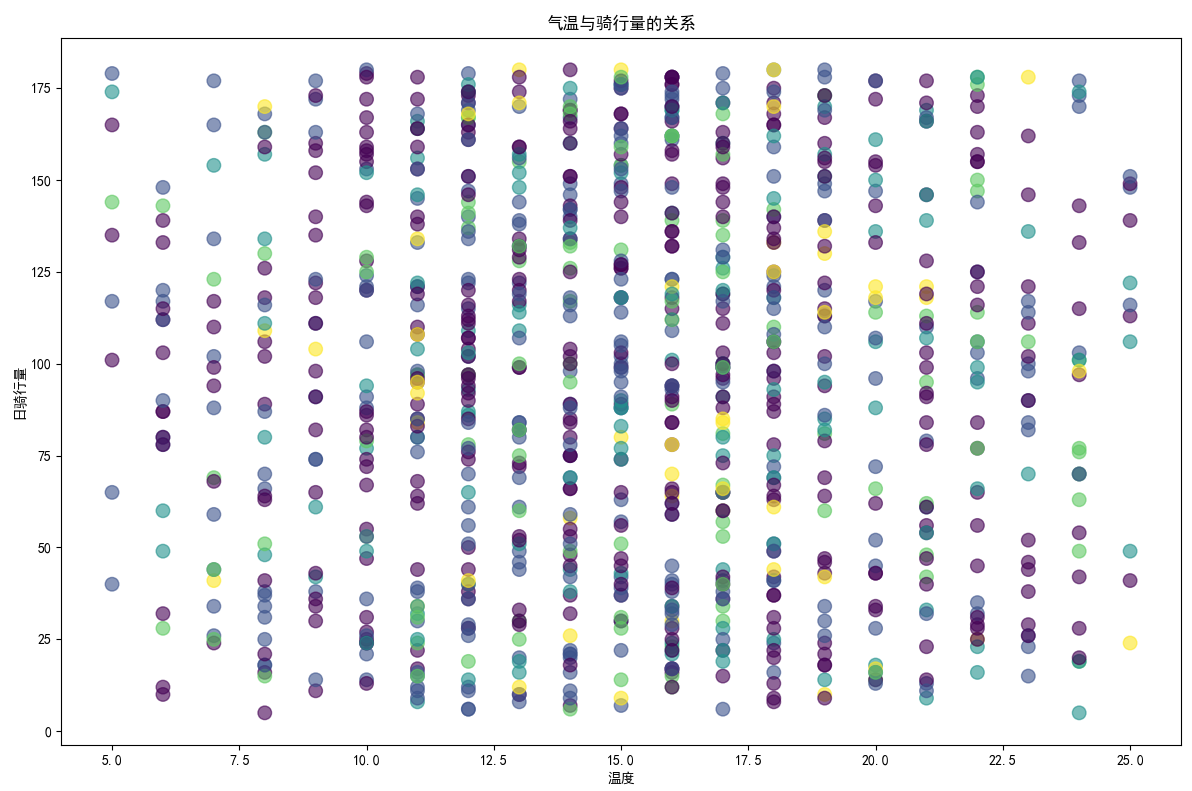 --- #### 气泡图 ```模板 import matplotlib.pyplot as plt import pandas as pd # 1. 数据聚合 grouped = df.groupby(group_by).agg({ x_value: 'mean', y_value: 'mean', group_by: 'count' # 计算每组的数量 }).rename(columns={group_by: 'count'}) # 2. 计算气泡大小 min_size = 50 max_size = 1000 sizes = (grouped['count'] - grouped['count'].min()) / \ (grouped['count'].max() - grouped['count'].min()) sizes = sizes * (max_size - min_size) + min_size # 3. 绘制气泡图 plt.figure(figsize=(10, 8)) plt.scatter(grouped[x_value], grouped[y_value], s=sizes, alpha=0.6) plt.xlabel(f'平均{x_value}') plt.ylabel(f'平均{y_value}') plt.title(f'{group_by}分布气泡图') plt.grid(True, alpha=0.3) plt.tight_layout() plt.show() ``` ```python import pandas as pd import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('house_sales.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=Fales # 绘制气泡图来展示各个市区的房源特性。气泡图中的横轴可以表示平均售价,纵轴表示平均面积,而每个气泡的大小代表该市区的房源销售数量; st=df.groupby('市区').agg({ '价格(万元)':'mean', '面积(㎡))':'mean', '小区':'count,' # 计算房源总数 }).rename(columns={'小区':'数量'}) # 自动计算气泡大小 min_size=50 max_size=1000 # 将房源数量映射到气泡大小范围 sizes=(st['数量']-st['数量'].min()/(st[''数量].max()-st['数量'].min()) sizes=sizes*(max_size-min_size)+min_size # 绘制气泡提 plt.scatter(st['价格(万元)'],st['面积(㎡)'],s=sizes) plt.xlabel('平均售价') plt.ylabel('平均面积') plt.title('各市区房源特性') plt.tight_layout() plt.show() ``` >i **气泡大小计算** >将原始数据归一化到0-1范围:(value - min) / (max - min) >将归一化后的值映射到指定的大小范围:normalized * (max_size - min_size) + min_size >这样可以确保气泡大小在视觉上有明显差异 输出结果: 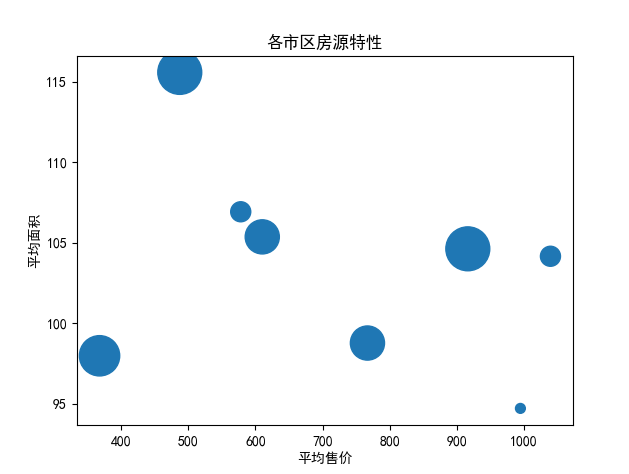 --- #### 雷达图 ```模板 import matplotlib.pyplot as plt import numpy as np def create_radar_chart(categories, values, title="雷达图"): """ 创建雷达图的通用函数 参数: categories - 维度标签列表 values - 对应维度的数值列表 title - 图表标题 """ # 计算角度 angles = np.linspace(0, 2*np.pi, len(categories), endpoint=False).tolist() angles += angles[:1] # 闭合雷达图 values_closed = values + values[:1] # 闭合数据 # 创建雷达图 plt.figure(figsize=(10, 8)) plt.subplot(polar=True) plt.plot(angles, values_closed) plt.fill(angles, values_closed, alpha=0.25) plt.xticks(angles[:-1], categories) plt.title(title) plt.tight_layout() plt.show() ``` ```python import pandas as pd import matplotlib.pyplot as plt import numpy as np # 读取数据 df=pd.read_csv('restaurant.csv') # 设置中文字体 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=Fales # 使用雷达图展示任意一家餐厅在卫生,服务,味道,环境四个唯独的评分 res=df.iloc[0] pf=[res['卫生评分'],res['服务评分'],res['味道评分'],res['环境评分']] bq=['卫生','服务','味道','环境'] # 角度计算 angles=np.linspace(0,2*np.pi,len(bq),endopint=False).tolist angles += angles[:1] pf_closed=pf+pf[:1] #创建雷达图 plt.figure(figsize=(12,8)) plt.subplot(polar=True) # 使用极坐标 plt.plot(angles,pf_closed) plt.fill(angles,pf_closed,alpha=0.25) plt.xticks(angles[:-1],bq) plt.title(f"{res['餐厅名称']}评分雷达表") plt.tight_layout() plt.show() ``` 输出结果: 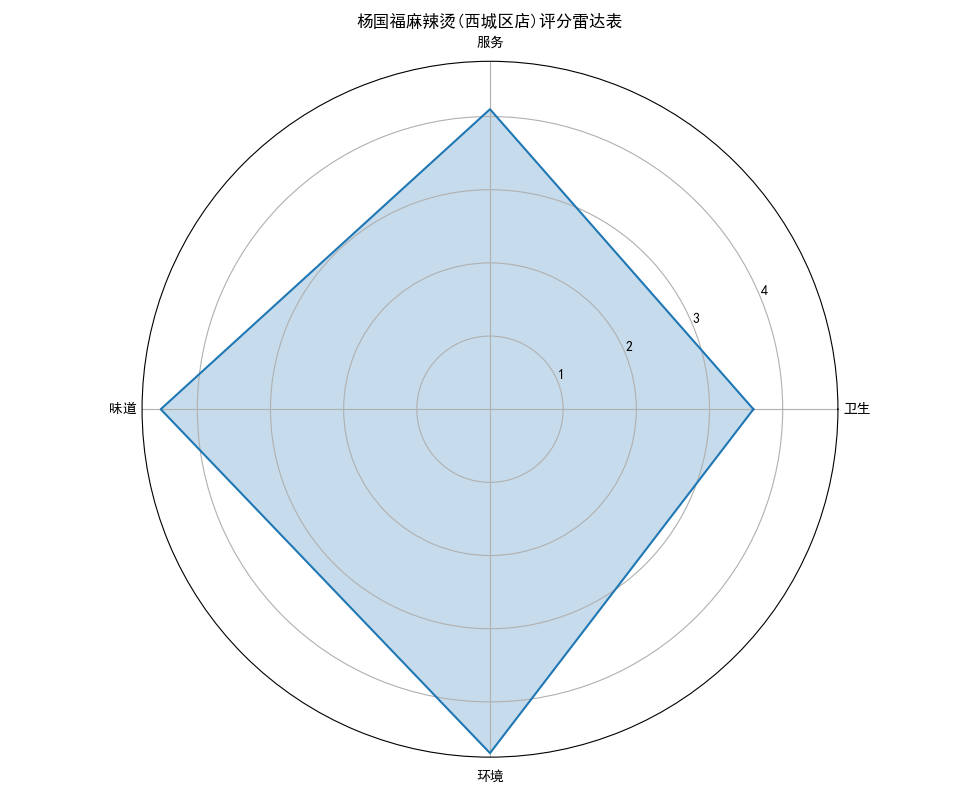 --- ```python import pandas as pd import matplotlib.pyplot as plt #读取数据 df=pd.read_csv('hotel_csv') plt.rcParams['font.sans-serif']=[SimHei] plt.rcParams['axes.unicode_minus']=Fales #使用雷达图展示任意一间酒店在卫生,服务,设施和位置评分的综合表现,雷达图中的每一个轴代表一个评分指标(卫生,服务,设施,位置),每个酒店表现为雷达图上的一个闭合路径 jd=df.iloc[1] pf=[jd['卫生评分'],jd['服务评分'],jd['设施评分'],jd['位置评分']] bq=['卫生','服务','设施','位置'] #计算角度 angles=np.linspace(0,2*np.pi,len(bq),endpoint=False).tolist angles += angles[:1] pf_closed=pf+pf[:1] # 创建雷达图 plt.figure(figsize=(12,8)) plt.subplot(polar=True) plt.plot(angles,pf_closed) plt.fill(angles,pf_closed,alpha=0.3) plt.xticks(angles[:-1],bq) plt.title(f"{jd['酒店名称']}综合表现雷达图") plt.tight_layout() plt.show() ``` 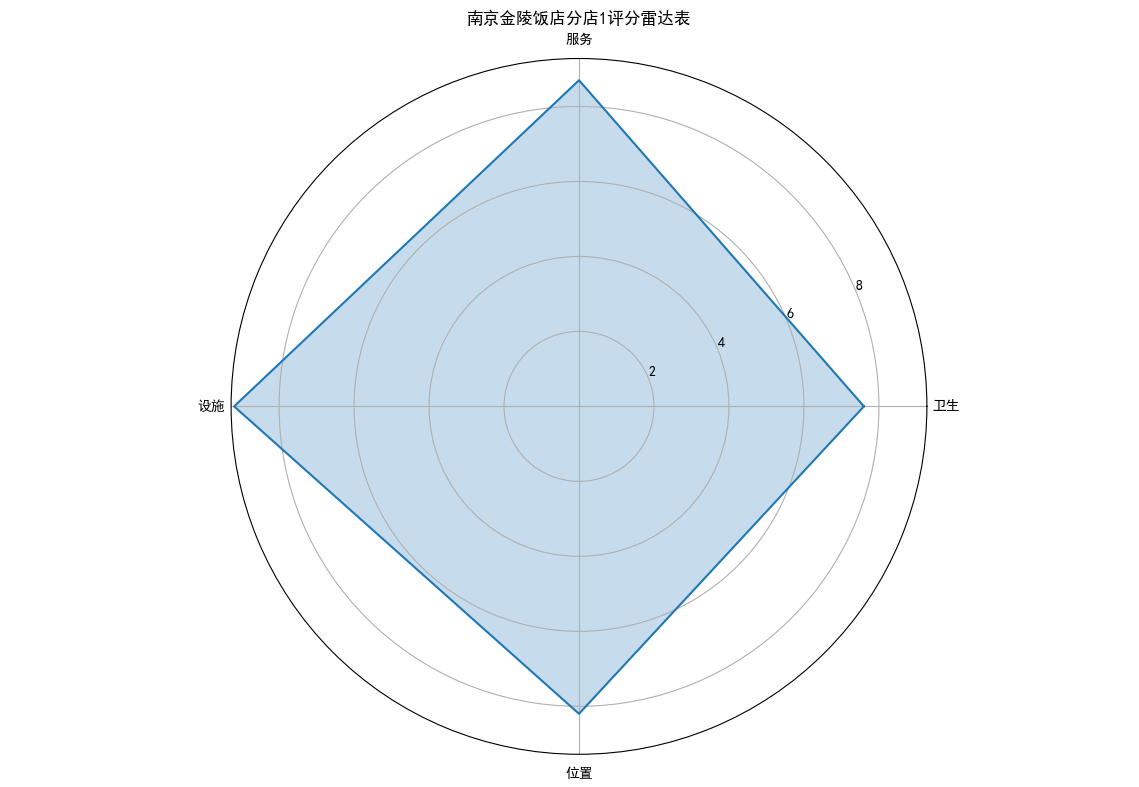 --- #### 饼图 ```python import pandas as pd import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('house_sales.csv') plt.rcParams['font.sans-serif']=[SimHei] plt.rcParams['axes.unicode_minus']=Fales # 绘制饼状图来展示不同 朝向的房源数量占比。每个扇区代表一种朝向,其大小该朝向房源的数量占总有房源的比例。 bt=df['朝向'].value_counts() plt.figure(figsize=(12,8)) plt.pie(bt,labels=bt.index,autopct='%1.1f%%') plt.title('不同朝向的房源数量占比') plt.tight_layout() plt.show() ``` 输出结果:  --- ```python import pandas as pd import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('sale_car.csv') plt.rcParams['font.sans-serif']=[SimHei] plt.rcParams['axes.unicode_minus']=Fales # 创建饼图展示不同车型在总销量中的占比,每个饼图切片代表一个车型你,其大小表示该车型在总销量中的份额 cx=df['车型'].value_counts() plt.figure(figsize=(12,8)) plt.pie(cx,labels=cx.index,autopct='%1.1f%%',labeldistance=1.1, pctdistance=0.8) plt.title('各车型销量占比',fontsize='20') plt.tight_layout() plt.show() ``` #### 玫瑰图 ==pyechars== ```python from pyecharts import options as opts from pyecharts.charts import Pie import pandas as pd df = pd.read_csv('../数据分析/house_sales.csv') # 统计装修情况 zx = df['装修情况'].value_counts() #使用 Pyecharts 绘制玫瑰图来展示不同装修情况的房源数量分布。其中每个条形的角度表示装修情况,而半径表示数量; #创建玫瑰图 rose = ( Pie() .add( '装修情况', # 图例名称 list(zx.items()), # 数据:将装修统计转换为(装修时间,数量)列表 radius=['30%','70%'], # 内外半径,控制图形大小 rosetype='radius' # 玫瑰图类型:半径表示数值大小 ) .set_global_opts( # 设置全局配置 title_opts=opts.TitleOpts(title='装修情况分布',pos_left='center'), #图表标题 legend_opts=opts.LegendOpts(orient='vertical',pos_left='left') # 图例:垂直排列,靠左 ) .set_series_opts( label_opts=opts.LabelOpts(formatter="{b}:{c}({d}%)") # 标签格式:名称:数量(百分比) ) ) rose.render('rose.html') ``` 输出结果 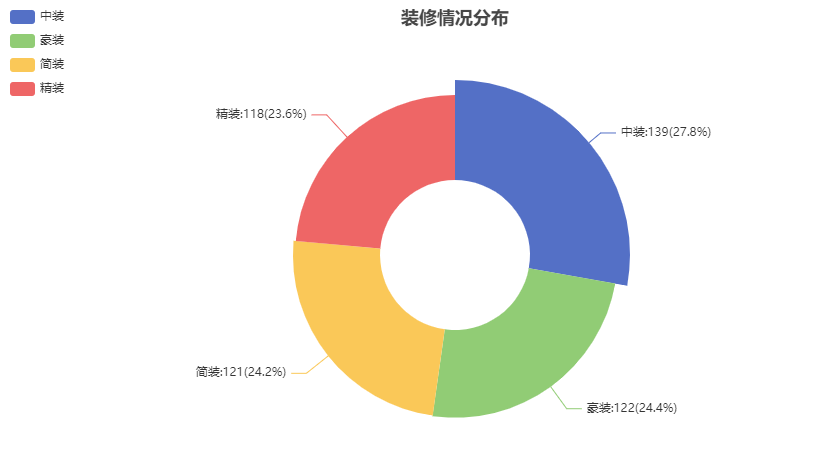 matplotlib ```python # 绘制玫瑰图来展示不同装修情况的房源数量分布。其中每个条形的角度表示装修情况,而半径表示数 # 直接使用value_counts()的结果 decoration_counts = df['装修情况'].value_counts() # 创建玫瑰图 plt.figure(figsize=(10, 8)) ax = plt.subplot(111, projection='polar') # 直接使用decoration_counts的索引和值 theta = np.linspace(0, 2*np.pi, len(decoration_counts), endpoint=False) width = 2 * np.pi / len(decoration_counts) # 绘制条形 - 直接使用Series的值 bars = ax.bar(theta, decoration_counts.values, width=width, alpha=0.7) # 设置角度标签 - 直接使用Series的索引 ax.set_xticks(theta) ax.set_xticklabels(decoration_counts.index) # 将装修情况名称设置为对应角度的标签,而不是数值 # 设置标题 plt.title('不同装修情况的房源数量分布') plt.show() ``` 输出结果: 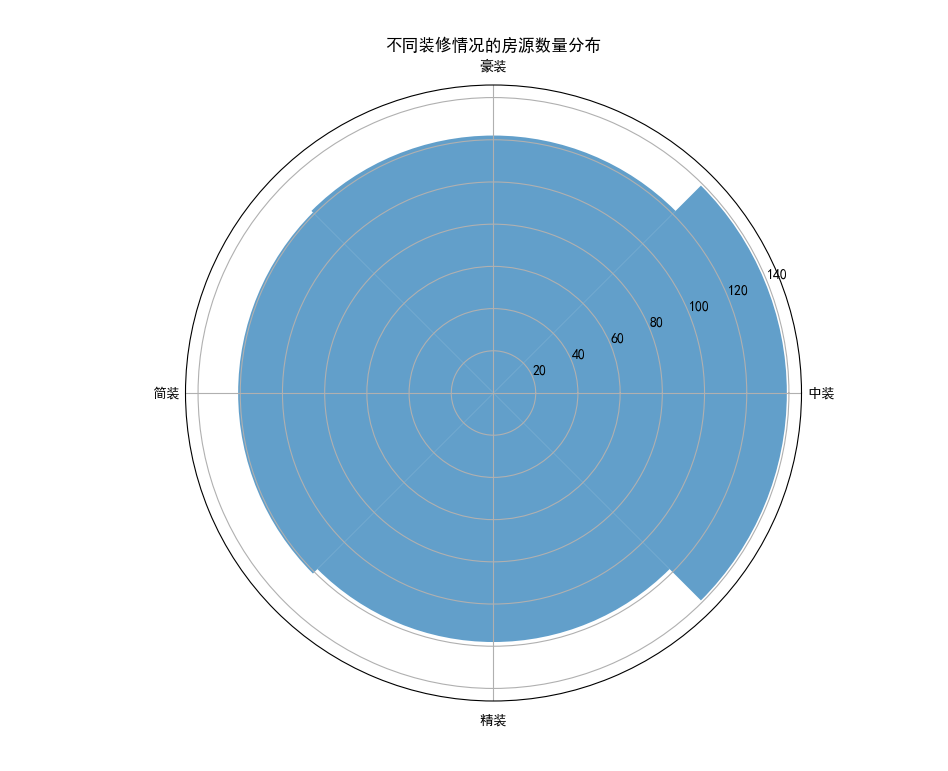 --- #### 折线图 ``` import pandas as pd import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('house_sales.csv') plt.rcParams['font.sans-serif']=[SimHei] plt.rcParams['axes.unicode_minus']=Fales # 使用折线图不同年份的二手房平均售价趋势 year =df.groupby('年份')['价格(万元)'].mean() plt.figure(figsize=(12,8)) plt.plot(year) plt.title('不同年份二手房平均售价趋势折线图') plt.xlabel('年份') plt.ylabel('平均售价') plt.tight_layout() plt.show() ``` 输出结果: 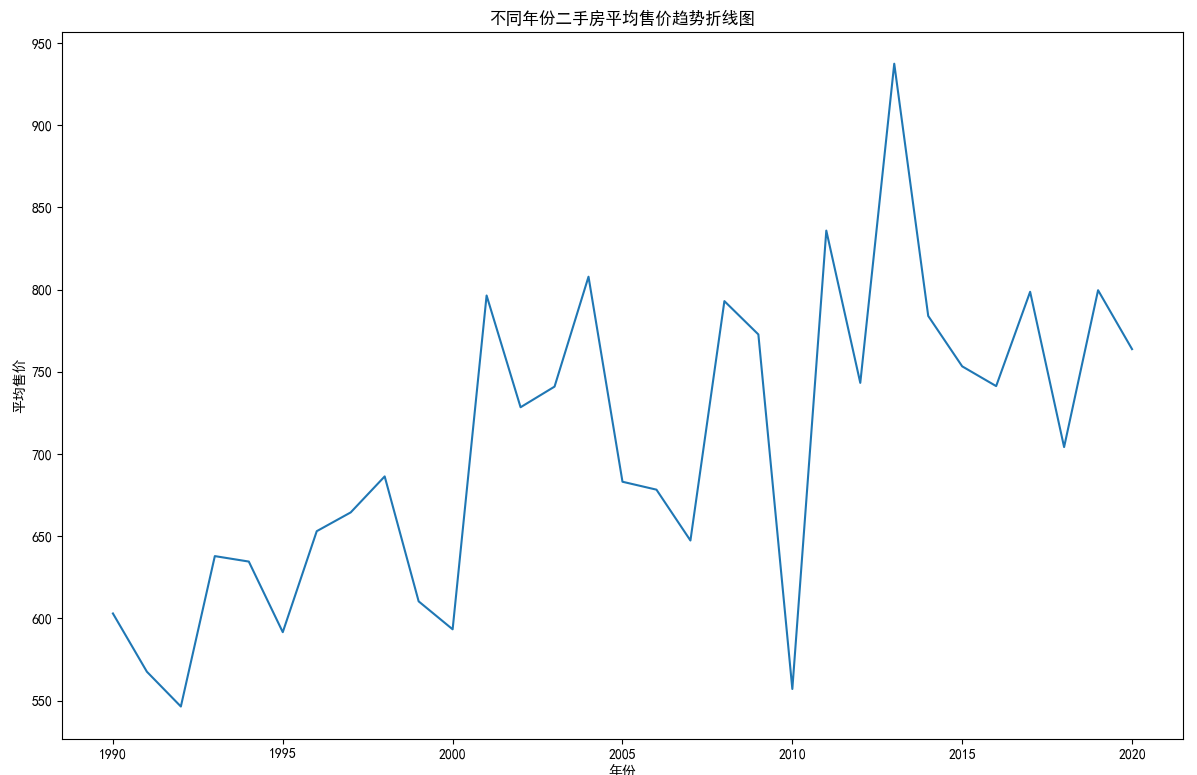 ``` import pandas as pd import matplotlib.pyplot as plt # 读取数据 df=pd.read_csv('bike_rides.csv') plt.rcParams['font.sans-serif']=[SimHei] plt.rcParams['axes.unicode_minus']=Fales # 使用折线图展示一天24小时内的骑行量变化趋势,图中需要包含工作日和周末两条折线,以便对比不同类型日期的使用模式差异 # 处理时间 df['开始时间']=pd.to_datetime(df['开始时间']) df['小时']=df['开始时间'].dt.hour # 分开工作日和周末 gzr=df[df['周末标记']==0] zm=df[df['周末标记']==1] # 统计每小时骑行量 gzr_tj=gzr.groupby('小时').size() zm_tj=zm.groupby('小时').size() # 画图 plt.figure(figsize=(12,8)) plt.plot(gzr_tj.index,gzr_tj.values,label='工作日') plt.plot(zm_tj.index,zm_tj.values,label='周末') plt.title('工作日和周末骑行量对比') plt.xlabel('小时') plt.ylabel('骑行量') plt.legend() plt.tight_layout() plt.show() ``` 输出结果: 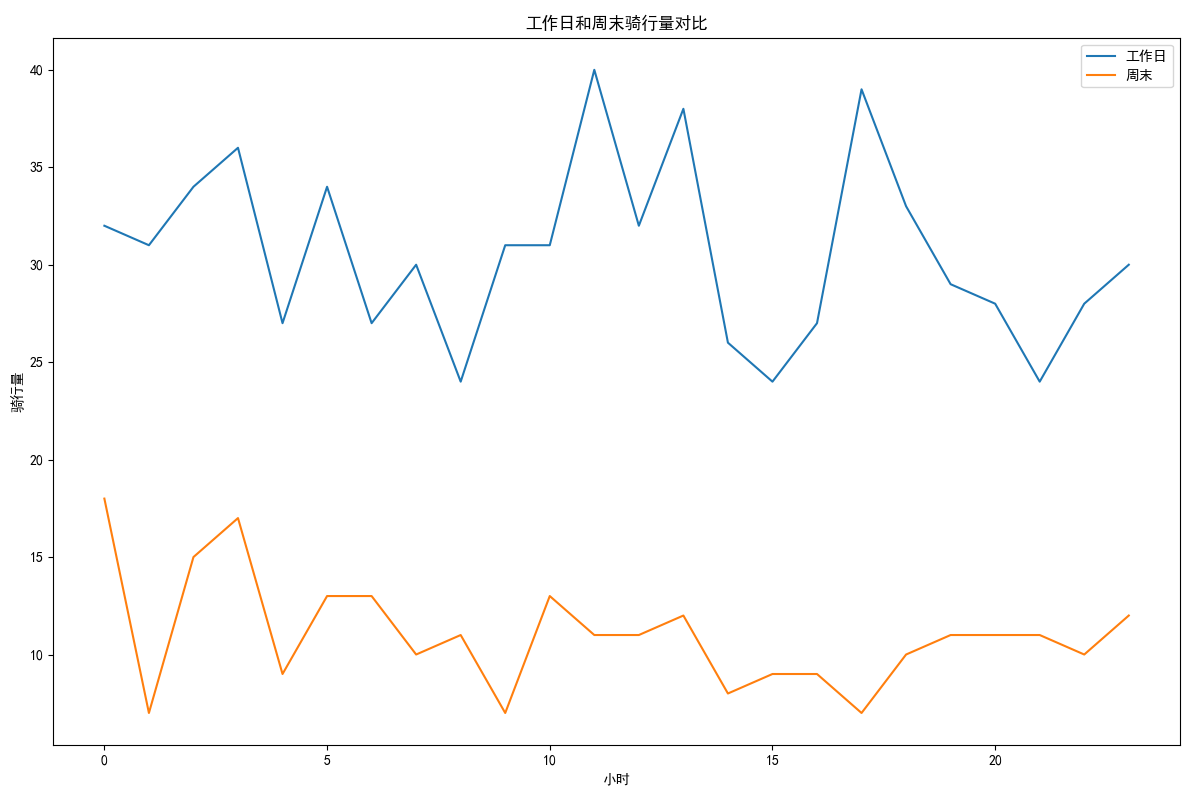 --- #### 热力图 seabron ```python import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取数据 df=pd.read_csv('../数据分析/bike_rides.csv') # 设置中文显示 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False # 创建时间热力图展示一周内各时段的骑行量分布,横轴为星期(周一至周日),纵轴为小时(0-23),颜色深浅表示骑行量的多少 df['开始时间']=pd.to_datetime(df['开始时间']) # 提取星期几 df['星期几']=df['开始时间'].dt.dayofweek # 提取小时 df['小时']=df['开始时间'].dt.hour # 创建数据透视表 pt=df.pivot_table( index='小时', columns='星期几', values='骑行ID', aggfunc='count', fill_value=0 # 如果某个时间段没有数据,填充为0 ) # 设置星期标签 wk=['周一','周二','周三','周四','周五','周六','周日'] # 创建图形 sns.heatmap( pt, cmap='YlOrRd', annot=False, linewidths=0.5, cbar_kws={'label':'骑行量'} ) # 设置坐标轴刻度标签 plt.xticks(ticks=[0.5,1.5,2.5,3.5,4.5,5.5,6.5],labels=wk) plt.tight_layout() plt.show() ``` 输出结果: 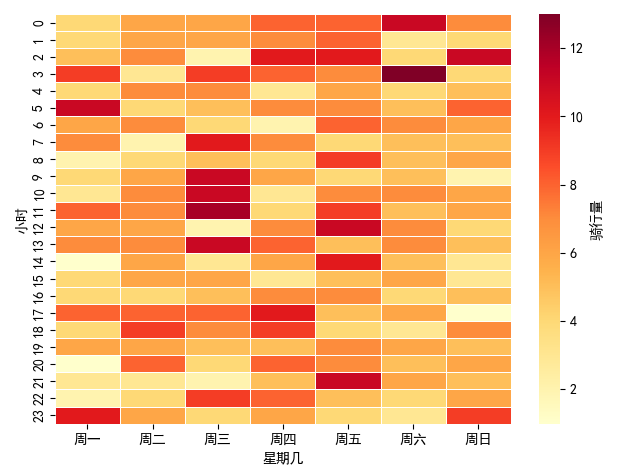
MARKJY
2025年11月3日 16:21
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码