2025莞纺大数据竞赛队
CentOS 7.9 大数据基础配置
Linux虚拟机IP分配
Hadoop+JDK配置
Zookeeper集群配置
Kafka配置
Hadoop搭建
数据可视化总结
数据分析总结
CentOS 7.9 基础指令大全
Flume安装配置
MySQL安装配置与运维
用户画像数据库表及数据.sql
本文档使用 OkDoc 发布
-
+
首页
数据分析总结
## 数据分析 什么是==数据分析==? 数据分析:对大量有序或无序的数据进行信息的集中整合、运算提取、展示等操作,通过这些操作找出研究对象的内在规律。 ==目的==:揭示事物运动、变化、发展的规律。 ==意义==:提高系统运行效率、优化系统作业流程、预测未来发展趋势。 --- ## pandas 什么是==pandas==? Pandas的名字来源于面板数据(Panel Data)与数据分析(data analysis)两个词的组合。它是一个开源的第三方 Python 库,从 NumPy 和 Matplotlib 的基础上构建而来的。它的目标是称为强大、灵活、可以支持任何编程语言的数据分析工具。它主要实现数据分析的五个重要环节: * 加载数据 * 整理数据 * 操作数据 * 构建数据模型 * 分析数据 pandas导入方式 ```python import pandas as pd ``` --- ## 数据分析分类汇总 数据分析任务都是使用pandas库,解决方法大致相同:使用pandas进行数据读取,分组,聚合,排序,筛选,计算等操作; 接下来进行数据分析任务的分类汇总: ### 类别1:分组计数并排序前n名 ==用法:== 这类分析用于识别重点区域或热门类别,帮助资源优化配置和市场战略制定。例如在商业布局中,了解哪个区域的餐厅数量最多,可以指导新店选址或广告投放。 ==解决方法:== 用==value_counts()==计数,然后排序,最后用head(N)取前N名; 适用任务: 餐厅主题 任务1:统计各地区餐厅数量,按降序排列并展示前两名 ```python ``` 输出结果: 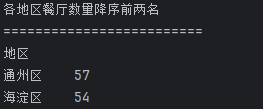 --- 二手房主题 任务1:统计每个市区的房源销售数量,倒序排序展示前三名 ```python ``` 输出结果: 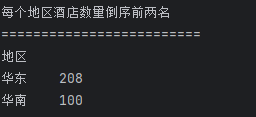 --- 共享单车主题 任务4:统计每个地区的起始和结束骑行次数,识别最热门的上车区域和下车区域(**需分别对起始区域和结束区域分组计数**) ```python ``` 输出结果: 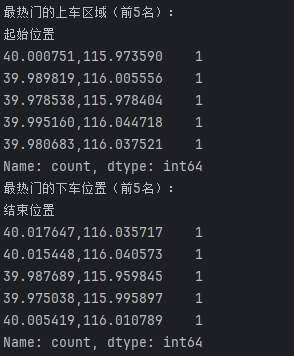 --- 餐厅主题 任务4:统计每种菜系类型的出现频次,按升序并展示前两名 ```python ``` 输出结果: 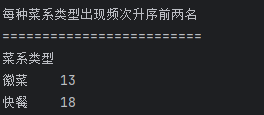 --- 二手房主题 任务4:统计不同装修情况的房源数量,正序排序展示(未指定前N名,但方法相同) ```python ``` 输出结果: 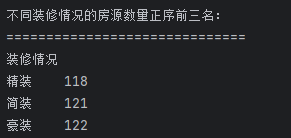 --- 酒店主题 任务4:统计每种房间类型出现的频次,正序排序展示前两名 ```python ``` 输出结果: 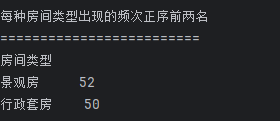 --- ==总结==:使用value_counts方法,可以更简洁地实现同样的功能,因为value_counts**默认**就是计算每个类别的频数并**降序排列** --- ### 类别2:分组平均并排序前N名 ==用法==:这类分析用于比较不同群体的表现差异。比如分析不同装修时间的平均设施评分,可以评估装修质量随时间的变化趋势 ==解决办法==:使用groupby()分组后,用mean()计算平均值,然后用sort_values()排序,最后用head()取前N名 适用任务: 餐厅主题 任务3:计算每个地区的人均消费平均值,按降序排列并展示前三名 ```python ``` 输出结果: 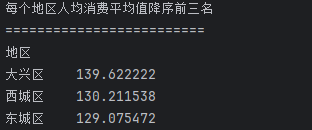 --- 二手房主题 任务2:计算各户型的平均售价,倒序排序展示前三名 ```python ``` 输出结果: 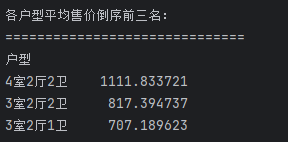 --- 二手房主题 任务3:计算每个市区的平均售价,并倒序排序出前三名; ```python ``` 输出结果: 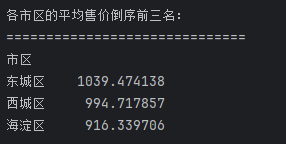 --- 酒店主题 任务3:计算每个地区的平均房价,倒序排序前三名 ```python ``` 输出结果: 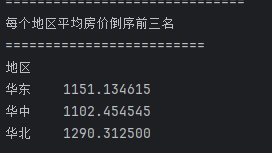 --- 汽车主题 任务2:计算每个厂商的年度总销量,倒序排序展示前五名(这个是计算总销量而不是平均) ```python ``` 输出结果: 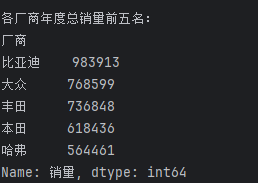 ---
MARKJY
2025年11月3日 16:22
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码